Note
Go to the end to download the full example code.
femorph-solver vs scikit-fem — mesh-size scaling#
Runs both backends across a range of in-plane mesh sizes (nx = ny)
at fixed nz = 2 and plots assembly / static / modal wall-time as a
function of DOF count on log-log axes.
This is the comparison that actually matters for real models: the per-stage wall-time on a 40×40 plate tells you very little about what happens at 200×200. Dense assembly in pure Python loses relative ground with mesh size because every element repeats the whole Python overhead; femorph-solver’s C++ batch kernel amortises that work.
Sweep#
We pick nx values spaced roughly by ~√2 so the DOF axis spans
about two decades. Each run is a complete solve — build, K/M
assemble, static, modal — using the same code paths the gallery
example exercises at a single mesh.
from __future__ import annotations
import time
from perf.compare.run_femorph_solver import run as run_femorph_solver
from perf.compare.run_skfem import run as run_skfem
NX_GRID = [10, 20, 40, 60, 80]
NZ = 2
N_MODES = 10
femorph_solver_runs = []
skf_runs = []
for nx in NX_GRID:
print(f"nx = {nx} …", flush=True)
t0 = time.perf_counter()
femorph_solver_runs.append(run_femorph_solver(nx, nx, NZ, n_modes=N_MODES))
print(f" femorph_solver {time.perf_counter() - t0:6.2f}s", flush=True)
t0 = time.perf_counter()
skf_runs.append(run_skfem(nx, nx, NZ, n_modes=N_MODES))
print(f" skfem {time.perf_counter() - t0:6.2f}s", flush=True)
nx = 10 …
femorph_solver 0.09s
skfem 0.59s
nx = 20 …
femorph_solver 0.54s
skfem 3.01s
nx = 40 …
femorph_solver 1.45s
skfem 51.56s
nx = 60 …
femorph_solver 4.24s
skfem 165.90s
nx = 80 …
pardiso not installed; at 58,320 DOFs it is typically 3x-5x faster than SuperLU/CHOLMOD on Intel hardware. Install with `pip install femorph_solver[pardiso]` to enable it in the auto solver chain. This message is emitted once per process.
femorph_solver 9.04s
skfem 304.34s
Numbers#
Print the raw per-stage wall-time at each mesh. The ratio column is scikit-fem time ÷ femorph-solver time — higher means femorph-solver is further ahead.
header = f"{'nx':>4} {'DOF':>8} {'stage':<12} {'femorph_solver (s)':>10} {'skfem (s)':>10} {'ratio':>8}"
print(header)
print("-" * len(header))
stages = [
("build", "t_build_s"),
("assemble_K", "t_assemble_K_s"),
("assemble_M", "t_assemble_M_s"),
("static", "t_static_s"),
("modal", "t_modal_s"),
]
for m, s in zip(femorph_solver_runs, skf_runs, strict=True):
for stage_name, attr in stages:
t_m = getattr(m, attr)
t_s = getattr(s, attr)
ratio = t_s / t_m if t_m > 0 else float("nan")
print(f"{m.nx:>4} {m.n_dof:>8} {stage_name:<12} {t_m:>10.4f} {t_s:>10.4f} {ratio:>7.1f}x")
nx DOF stage femorph_solver (s) skfem (s) ratio
-------------------------------------------------------------------
10 1089 build 0.0057 0.0359 6.3x
10 1089 assemble_K 0.0047 0.4764 101.2x
10 1089 assemble_M 0.0025 0.0368 14.5x
10 1089 static 0.0159 0.0130 0.8x
10 1089 modal 0.0569 0.0299 0.5x
20 3969 build 0.0101 0.1489 14.8x
20 3969 assemble_K 0.0146 2.3088 158.4x
20 3969 assemble_M 0.0052 0.1562 30.1x
20 3969 static 0.1784 0.1518 0.9x
20 3969 modal 0.3163 0.2349 0.7x
40 15129 build 0.0276 0.8145 29.6x
40 15129 assemble_K 0.0331 47.7346 1443.1x
40 15129 assemble_M 0.0147 0.7787 53.0x
40 15129 static 0.4220 0.8731 2.1x
40 15129 modal 0.9130 1.3196 1.4x
60 33489 build 0.0567 3.3218 58.6x
60 33489 assemble_K 0.0778 154.6149 1988.3x
60 33489 assemble_M 0.0444 1.5932 35.9x
60 33489 static 1.3423 2.5401 1.9x
60 33489 modal 2.6420 3.7599 1.4x
80 59049 build 0.0948 7.0764 74.6x
80 59049 assemble_K 0.1337 276.1827 2065.3x
80 59049 assemble_M 0.0857 3.8806 45.3x
80 59049 static 2.9907 7.3011 2.4x
80 59049 modal 5.6057 9.7642 1.7x
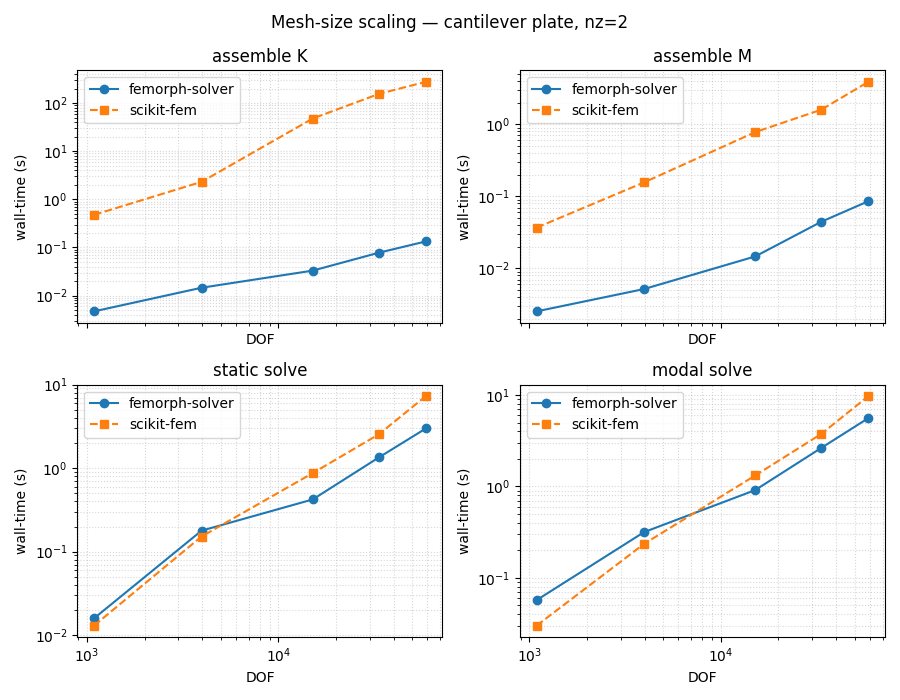
Scaling plot#
One panel per stage (assemble K, assemble M, static, modal). Log-log
so power-law scaling looks linear. The interesting reading is the
slope: both solvers should scale O(n_dof) on assembly (roughly
linear) and O(n_dof^{~1.3}) on the sparse direct solve.
import matplotlib.pyplot as plt # noqa: E402
dofs = [m.n_dof for m in femorph_solver_runs]
fig, axes = plt.subplots(2, 2, figsize=(9, 7), sharex=True)
panels = [
("assemble K", "t_assemble_K_s", axes[0, 0]),
("assemble M", "t_assemble_M_s", axes[0, 1]),
("static solve", "t_static_s", axes[1, 0]),
("modal solve", "t_modal_s", axes[1, 1]),
]
for title, attr, ax in panels:
ax.loglog(dofs, [getattr(m, attr) for m in femorph_solver_runs], "o-", label="femorph-solver")
ax.loglog(dofs, [getattr(s, attr) for s in skf_runs], "s--", label="scikit-fem")
ax.set_title(title)
ax.set_xlabel("DOF")
ax.set_ylabel("wall-time (s)")
ax.grid(True, which="both", ls=":", alpha=0.5)
ax.legend()
fig.suptitle(f"Mesh-size scaling — cantilever plate, nz={NZ}")
fig.tight_layout()
plt.show()
Total running time of the script: (9 minutes 1.872 seconds)